Migrer de CommonJS vers ECMAScript Modules - #2

Y’a quoi au menu ?
Cet article est la suite de la théorie sur la migration ESM. Il explique comment nous nous y sommes pris pour migrer l’API du monorepo Pix.
Si vous n’avez que cinq minutes, lisez la stratégie.
Si vous avez un peu plus de temps, choisissez dans le menu.
Voilà les plats principaux :
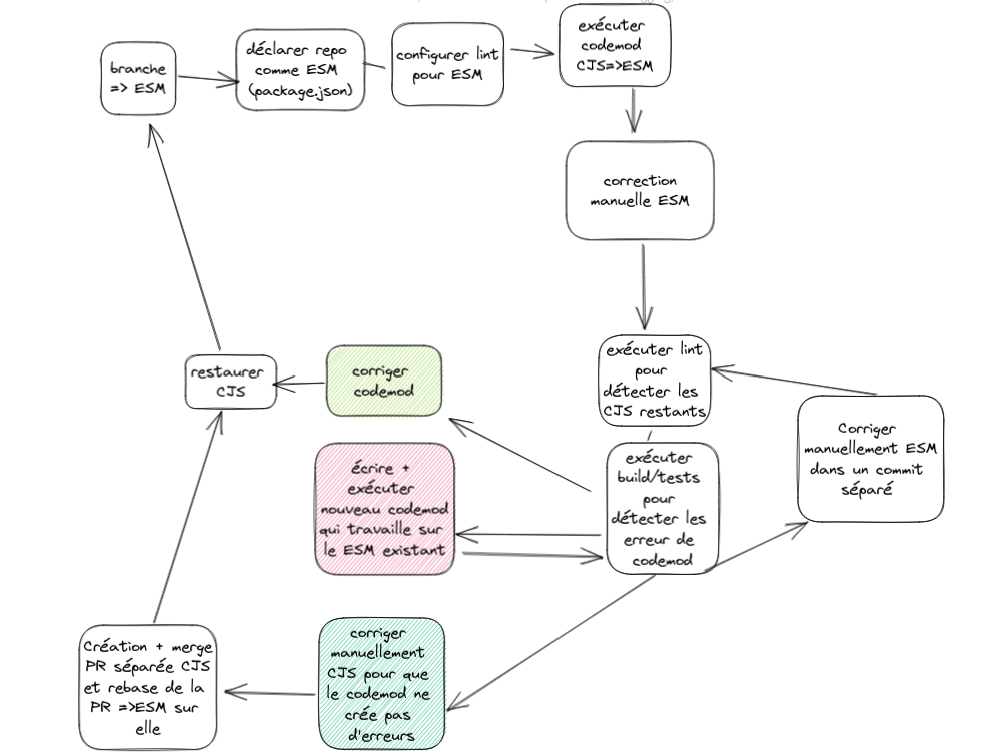
- monter et faire vivre l’équipe dédiée ;
- la stratégie de migration ; un zoom sur deux décisions d’implémentation de la codebase ;
- faire de la mise en production un non-évènement.
Et si vous êtes gourmands, lisez tout du début à la fin…
L’équipe
Traiter les besoins internes
Chez Pix, le développement est effectué par des Feature Teams (FT), qui reçoivent les besoins utilisateurs principalement du Product Owner (PO). Les développeurs peuvent participer au recueil et au raffinement du besoin, et le questionner lors de l’implémentation (le détail est expliqué ici).
Les besoins d’amélioration interne au pôle engineering, dont fait partie la migration ESM, suivent un processus particulier, appellé “Impact Team”. Des développeurs sont détachés de leur équipe pour un temps défini, en général quelques semaines, avec un objectif clair, même si le sujet est exploratoire.
Pour la migration ESM, un développeur a fait une présentation de 15 minutes à tous les autres développeurs, en exposant le besoin et la solution qu’il proposait. Il a ensuite proposé qu’un autre développeur, volontaire, le rejoigne pour deux semaines afin de réaliser la migration.
Travailler ensemble
La taille de l’équipe, 2 personnes, est importante :
- suffisamment grande pour résoudre le problème théorique et permettre les absences ponctuelles ;
- suffisamment petite pour minimiser le surcoût de coordination.
Le développement, dès le début, s’est fait en pair programming, en rotations de 30 minutes, la plupart du temps en présentiel. Le pair programming est encouragé chez Pix et il a été crucial ici : répartir la connaissance, trouver les solutions et se soutenir lorsqu’il fallait effectuer des corrections manuelles.
Les corrections manuelles ont aussi été faites en pair programming, même si on pense spontanément à paralléliser les tâches répétitives. En effet, la personne qui ne code pas, pendant que son partenaire modifie les fichiers :
- signale les erreurs d’inattention ;
- pense aux cas qui ne sont pas couverts ;
- suggère de meilleurs moyens d’effectuer la correction (ex: grouper les fichiers) ;
- prend du recul sur ce qui se passe.
Être deux nous a aussi permis de prendre soin l’un de l’autre et de mener à bien la migration. Seuls, nous n’aurions pas reconnu la fatigue et aurions persisté dans des solutions qui étaient des impasses. Mon ressenti est qu’il a été plus facile de prendre soin de l’autre que de moi-même, et que l’autre me rappelait quand je ne prenais pas soin de moi. Et vice-versa, dans un cercle vertueux.
En plus de cette boucle de feedback de 30 minutes, il y avait une boucle quotidienne. La journée commençait avec un partage de 15 minutes de l’avancée avec les CTO, sur la base d’un résumé fait en fin de journée sur le Wiki interne. Cela permet de s’assurer que nous étions sur le bon chemin, et d’envisager des actions pour enlever des obstacles, par exemple demander de l’aide en dehors de l’équipe.
Ce partage quotidien a assuré la confiance. Lorsque les deux semaines initialement imparties étaient écoulées, les CTO ont décidé que la migration pouvait être poursuivie, sachant que nous traitions les risques les plus importants en premier. Si la migration s’avérait impossible, ils le sauraient rapidement et pourraient décider d’arrêter le chantier.
Ne gardons pas le suspense plus longtemps, d’autant que la présentation de l’article le mentionne : la migration a pris deux mois au lieu des 2 semaines annoncées (ce qui était prévisible après tout).
La stratégie
Parler de stratégie n’est pas tout à fait honnête, car nous n’avions pas de plan, uniquement quelques principes. Nous partageons ici notre expérience pour vous aider à en avoir une si vous vous lancez dans l’aventure.
Un feedback rapide ?
Nous n’avons envisagé la migration que parce que nous avions des tests automatisés avec une bonne couverture.
La démarche classique de refactoring (car c’en est un) aurait été de migrer un fichier (SUT) en ESM et de vérifier que le test passe toujours. Le test (CJS) importerait le SUT (ESM), qui lui-même importerait des dépendances (ESM). Pour cela, il faudrait que ESM et CJS soient interopérables, et bien que le sujet commence à être implémenté et documenté, l’investissement ne semblait pas être un bon compromis.
Nous pensions procéder en trois étapes :
- migrer l’implémentation et effectuer un test manuel, à savoir démarrer l’API ;
- exécuter les tests automatisés de bout en bout (front + back) ;
- migrer les tests automatisés de l’API puis les exécuter.
La conséquence était la suivante : pendant la première partie, nous n’avions plus aucun test qui nous couvrait. Autrement dit : nous modifions la moitié de la codebase sans savoir si nos modifications étaient correctes. Même la vérification statique (lint) n’a pas fonctionné tout de suite, car un fichier dont le code est invalide ne peut être parsé. Les modifications étant effectuées par des codemods et des modifications manuelles, si elles se révélaient incorrectes et qu’il fallait les rejouer, nous n’étions pas à l’abri de devoir refaire ces actions manuelles.
Lorsque les deux semaines se sont allongées, nous ressentions de plus en plus cette épée de Damoclès. À la prochaine migration de codebase, il serait judicieux de remettre en cause cette stratégie.
Des compromis, encore et toujours
Dès le début, nos réflexes de développement ont été mis à rude épreuve. Voilà les observations des équipes sur le travail de l’impact Team.
La migration a duré deux mois au lieu des deux semaines annoncées.
Son développement a duré un mois et demi et la mise en production 15 jours. La PR principale modifiait la moitié de la codebase, et devait être rebase manuellement avant chaque livraison. Elle comportait 130 commits, dont une centaine pour les corrections manuelles. Les codemods ont été écrits par l’équipe en charge de la migration, ne sont pas dans la codebase et ne sont pas réutilisables. La manière de travailler de l’impact team ne semble pas leur avoir simplifié la vie.
Nous avons pourtant travaillé dur pour que la solution soit simple et viable, ce qui nous fait dire : La solution la plus simple n’a pas toujours l’air d’être la plus simple. Faire des compromis est un challenge intellectuel.
Tout d’abord, nous n’avons pas utilisé les codemods de la communauté. Bien qu’ils traitent une partie du problème, leur compréhension et leur extension auraient pris plus de temps qu’une réécriture. Nous avons décidé d’écrire nos propres codemods, et d’en écrire le moins possible. Pourquoi ? Parce que cela demande un investissement conséquent pour s’assurer que seul le code à modifier est modifié. Nous avons écrit des tests unitaires pour vérifier que le code n’est pas modifié, mais cela ne couvre que les cas que nous avons identifié. De plus, ils ne testent pas le comportement lorsque les codemods sont appliqués successivement sur un même fichier : des dépendances temporelles peuvent se produire.
Ensuite, nous avons choisi à de nombreuses reprises de migrer manuellement le code. Cela correspond à deux cas distincts : le code CJS est complexe à migrer en ESM, ou le cas est très peu présent. Nous préférons de loin développer des codemods et nous avons acquis de l’expérience, mais comme expliqué ci-dessus, nous avois choisi d’en écrire le moins possible.
Et pour finir, nous avons travaillé sur plusieurs branches/PR CJS et sur une seule branche/PR ESM. Lorsqu’une fonctionnalité CJS est difficile à migrer en ESM, on la remplace par une autre fonctionnalité CJS, elle-même plus facile à migrer, couverte par les tests et mergeable de suite. Ces modifications ont été faites par codemods (CJS → CJS) et manuellement.
Le résultat final de toutes ces contraintes est un état d’esprit que nous avons appelé “codemodception”. Lorsque nous identifions une syntaxe CJS non traitée, nous pensons à la manière la plus efficace de le faire entrer dans des cas déjà traités. Cela demande une bonne connaissance de la syntaxe CJS et ESM, de mémoriser les codemods et leur enchaînement.
Deux choix d’implémentation de la codebase
Nous avons conservé les fonctionnalités existantes d’import/export lorsque cela était possible. Dans deux cas exposés ci-dessous, nous avons fait des choix structurants d’implémentation, après avoir consulté toutes les équipes et validé la solution ensemble.
Les exports nommés
Les exports nommés ont des avantages, et nous trouvons important celui de l’amélioration de la maintenabilité du code : permettre l’import sélectif des composants d’un module. En l’absence de standards sur ce point, le codebase CJS contenait des exports nommés et des exports anonymes.
Nous avons proposé aux équipes de choisir :
- garder la situation existante : permettre les exports nommés et anonymes ;
- utiliser uniquement des exports nommés, en transformant les exports anonymes via des codemods.
La solution n°2, la suppression des exports anonymes, a été choisie. Elle comporte tout de même un inconvénient : si un fichier n’exporte qu’un seul composant, le développeur est obligé de lui trouver un nom, alors que le nom du fichier contient déjà toute l’information nécessaire.
Cette décision aurait pu être prise indépendamment de la migration ESM, mais la prendre de suite nous permettait de ne pas écrire de codemod ESM d’export/export anonymes, dont la syntaxe est complexe.
Nous l’avons mise en œuvre en CJS avec un codemod, partant du principe que le nom de l’import anonyme existant était celui du fichier, transposé de snake-case en PascalCase. C’est un usage que nous avions constaté dans la plupart des fichiers, mais il y a bien eu des exceptions, que nous avons corrigées manuellement.
La PR a ainsi pu être envoyée en production au plus tôt
Les tests et l’injection de dépendance
Lorsque l’API démarrait enfin, et que les tests manuels et de bout-en-bout passaient, nous avons entamé la migration des tests automatisés API. Le message qui allait hanter les jours suivants apparut très vite :
ES Modules cannot be stubbed.
Il provient de la librairie de test SinonJs, dans les tests unitaires, lorsque dans la section “Given” du test, nous remplaçons un composant importé par une doublure de test. Pour faire court, les exports CJS sont mutables alors que les exports ESM sont immutables (pour être précis, on parle de live bindings. La conséquence : tous les tests qui substituent une doublure de tests à un composant importé ne sont plus valables en ESM.
Après quelques jours à explorer les librairies de doublure, nous nous sommes rendus à l’évidence : le problème n’est pas ESM, mais le fait que nous n’avons pas injecté les dépendances à plusieurs endroits dans l’API. Si nous l’avions fait, au lieu de substituer une doublure de test dans un import, nous aurions injecté dans le composant à tester la doublure de test (voir cet exemple).
Nous avons longuement réfléchi à la solution :
- écrire un codemod qui injecterait les dépendances ;
- injecter manuellement les dépendances ;
- écrire un codemod qui encapsulerait les exports dans un objet, contournant ainsi le problème en rendant mutables les exports.
Nous avons fini par conclure que l’injection de dépendances, bien que plus verbeuse, était souhaitable. Elle rend explicite les dépendances d’un module, et rend les tests plus compréhensibles. Il n’est plus nécessaire de connaître le pattern proxy et son implémentation en Javascript pour comprendre comment fonctionnent les tests.
Il est apparu assez rapidement qu’injecter les dépendances via un codemod était complexe, et comme la migration avait du retard, nous avons préféré une solution manuelle dont le temps pouvait être prévu à une solution automatisée dont le temps était difficilement prévisible. Nous avons recensé le volume de fichiers à modifier en modifiant le code source de SinonJs pour qu’il mentionne le nom du module : pour chaque composant d’un module utilisant un composant importé, on ajoute la dépendance en tant que paramètre du composant à tester (on utilise une valeur par défaut), et on modifie le test pour injecter la doublure au lieu du composant. Cela donnait un total de 500 fichiers.
Nous avons décidé de demander de l’aide aux autres équipes, sur base du volontariat, pour effectuer ces corrections manuelles en CJS. Durant deux après-midi, après un exposé du principe, chaque groupe de quelques personnes injectait manuellement les dépendances sur un périmètre défini.
En approchant de la production
Après quelques semaines de développement, il est devenu clair que le sujet était bien plus complexe que nous ne l’imaginions. Même une fois que tous les tests automatisés passaient, des comportements imprévus pouvaient apparaître en production. Nous avons alors décidé de demander de l’aide à l’équipe en charge à mitiger les risques liés au changement, l’équipe captains. Une seule séance de brainstorming de deux heures a permis de trouver une stratégie pour sécuriser ce changement. Je vous l’expose ici.
Le suivi et la motivation
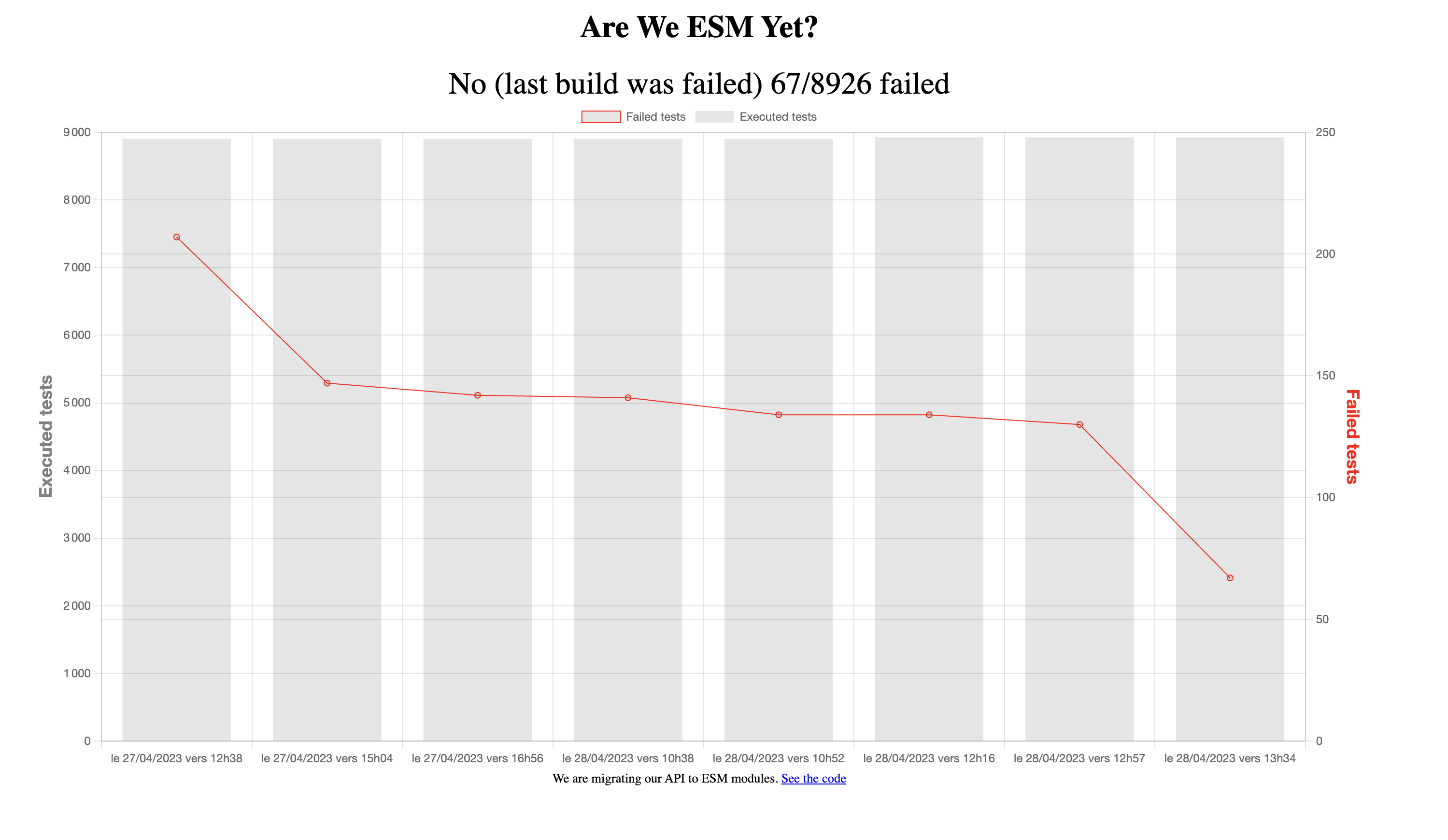
L’état et la vitesse d’avancement de la migration n’était pas très visible, aussi l’équipe captains a affiché en dynamique l’état des tests automatisés sur Are we ESM yet ?. C’est une Github page qui interroge la CI via une API : simple et efficace. Elle rend le travail et les difficultés visibles à tous.
Sécuriser le déploiement
Pour vérifier le comportement d’ESM, la production était le meilleur endroit. Le tout était de limiter l’impact qu’un problème éventuel aurait pu avoir si cela se produisait.
Nous avons listé des scénarios que nous avons priorisés par ordre d’importance décroissant :
- les utilisateurs internes de Pix, dans l’interface d’administration ;
- les utilisateurs externes de Pix, dans des usages non critiques ;
- les utilisateurs externes de Pix, dans des usages critiques, à savoir le passage de certification.
Ensuite, nous avons réfléchi à la manière d’utiliser ESM sur une fraction du traffic API dans ces scénarios.
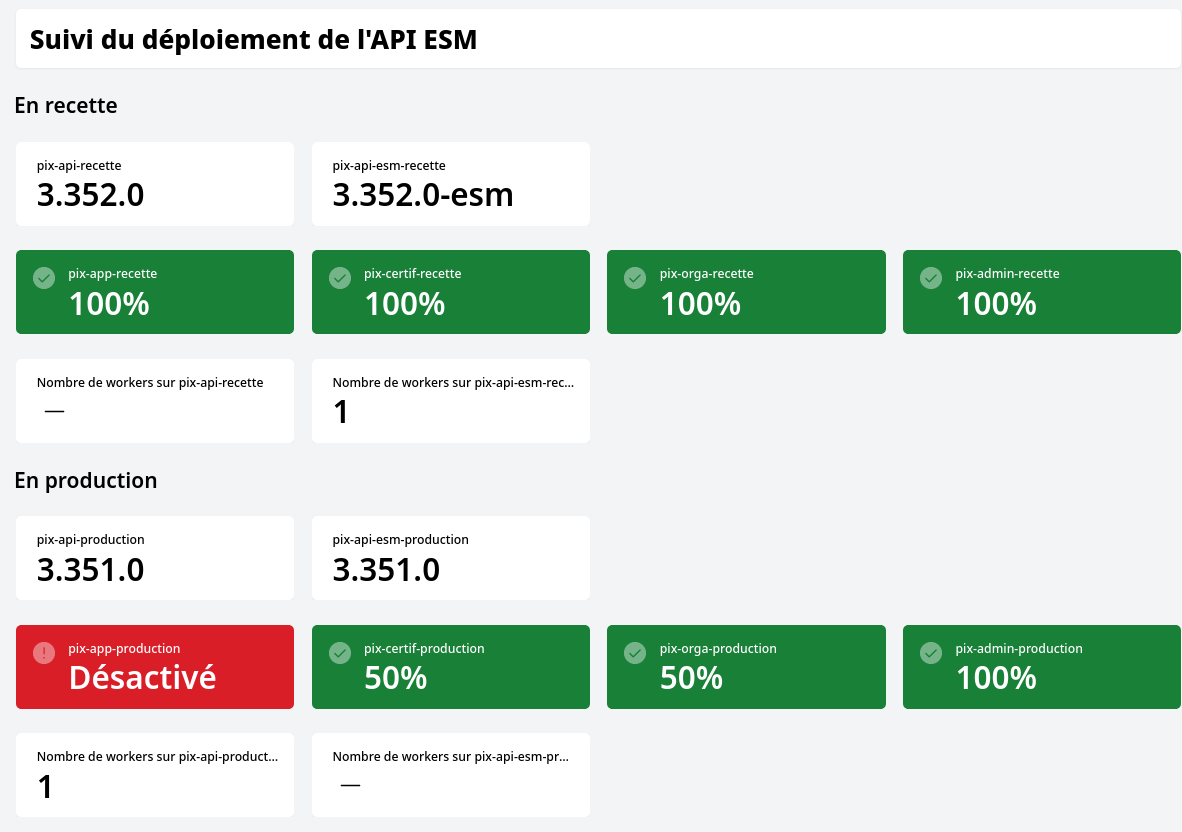
Nous avons fini par trouver une implémentation satisfaisante de ce qui est connu sous le nom de canary release : deux instances d’APi tournent simultanément : l’une en CJS, l’autre en ESM. On paramètre les front-end pour qu’ils envoient progressivement une partie des requêtes sur la version ESM.
Un tableau de suivi Steampipe donne une vue d’ensemble de la situation.
Voilà un exemple à mi-chemin de l’expérimentation : les front-end utilisent ESM pour une requête sur deux, sauf l’application principale. Les traitements asynchrones (workers) utilisent déjà uniquement la version ESM.
Happy end
Le 1er juin 2023, 3 mois après avoir donné le coup d’envoi, toute la production tourne en ESM !! Le changement a été un non-événement.

And finally, monsieur, a wafer-thin mint
Le code
Voilà la pull request principale :
- +35/-40 k fichiers
- 132 commits
- les codemods.
Canary release
Le canary release a été implémenté avec ningx depuis les serveurs front-end.
Il était paramétrable dynamiquement via des scripts bash, en modifiant les variables d’environnement du PaaS via le CLI.
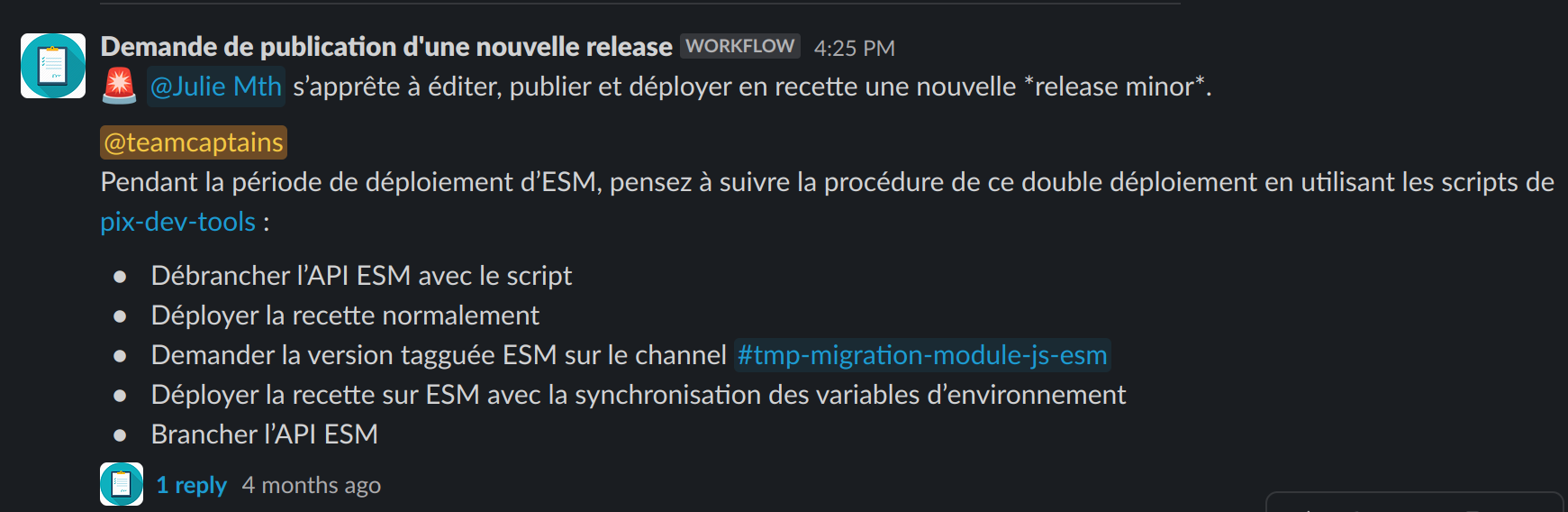
Il a complexifié le workflow de déploiement, en ajoutant des interventions manuelles à un workflow sur lequel les PO étaient autonomes.

Nous avons limité la complexité de coordination entre PO et développeurs en modifiant le workflow de déploiement Slack, pour y mentionner les actions manuelles.
Coût de coordination et complexité
Un problème qui ne peut être résolu seul demande de la coordination, qui a un coût.
In tasks that can be partitioned but which require communication among the subtasks, the effort of communication must be added to the amount of work to be done. The added burden of communication is made up of two parts, training and intercommunication. Each worker must be trained in the technology, the goals of the effort, the overall strategy, and the plan of work. This training cannot be partitioned, so this part of the added effort varies linearly with the number of workers. Intercommunication is worse. If each part of the task must be separately coordinated with each other part, the effort increases as n(n-1)/2. Three workers require three times as much pairwise intercommunication as two; four require six times as much as two.
If, moreover, there need to be conferences among three, four, etc., workers to resolve things jointly, matters get worse yet. The added effort of communicating may fully counteract the division of the original task
in Fred Brooks, The mythical man-month, Chapter “The Man-month”, page 18
Estimation
L’informatique n’est plus si jeune, les développeurs non plus, et nous sommes toujours obstinément optimistes. Le mystère reste entier..
All programmers are optimists.
Perhaps this modern sorcery especially attracts those who believe in happy endings and fairy godmothers. Perhaps the hundreds of nitty frustrations drive away all but those who habitually focus on the end goal. Perhaps it is merely that computers are young, programmers are younger, and the young are always optimists.
But however the selection process works, the result is indisputable: ‘This time it will surely run,’’ or “I just found the last bug.”. So the first false assumption that underlies the scheduling of systems programming is that all will go well, i.e., that each task will take only as long as it “ought” to take.
in Fred Brooks, The mythical man-month, Chapter “Optimism”, page 15