Passer une PK de INT en BIGINT en zéro downtime

TL;DR
Dans quelques mois, la table la plus volumineuse (nombre de lignes) aurait épuisé les valeurs disponibles pour sa clef primaire. Pour éviter cette situation, nous souhaitions changer de type en minimisant l’impact utilisateur, en visant des migrations de BDD “zero-downtime”.
Nous avons réussi et partageons avec vous nos apprentissages. Pour les impatients, la solution est ici.
Ceci dit, cela a eu lieu dans des circonstances particulières :
- table non référencée par d’autres tables ;
- trafic réduit (vacances).
Nous avons prévu de migrer d’autres tables, référencées, en charge nominale. Nous partagerons les résultats dans un autre article.
Motivation
En un an, depuis septembre 2020, la fréquentation de Pix a augmenté de manière spectaculaire. La charge a été bien absorbée par l’infrastructure, mais nous nous sommes rendu compte d’une autre conséquence: une table allait épuiser l’identifiant utilisé par sa clef primaire.
Il est bien sûr possible de modifier le type de cette propriété avec l’instruction native ALTER TABLE foo ALTER COLUMN id SET DATA TYPE BIGINT, mais cela a un coût proportionnel au remplissage de la table. Une exécution de cette instruction sur les données de production, sur un environnement moins puissant, a duré 8 heures.
Nous souhaitions trouver une alternative, à savoir effectuer ce changement sans que les utilisateurs ne s’en rendent compte :
- pas d’interruption de service, même sous la forme d’une fenêtre de maintenance planifiée ;
- pas de dégradation sensible des temps de réponse pendant les opérations.
Recherche de solution
Ce thread Stack Overflow est un excellent point d’entrée sur le sujet.
Deux solutions y sont proposées :
- soit utiliser une colonne temporaire ;
- soit utiliser une base de données temporaire, alimentée par une réplication logique.
Nous avons choisi la colonne temporaire, car cette solution peut être mise en œuvre immédiatement dans notre environnement.
En effet, nous utilisons les services d’un PaaS, Scalingo, et sommes heureux de ne pas avoir à installer et maintenir nos bases de données. Le service spécifique de la réplication logique n’est pour l’instant pas offert.
Examinons pour commencer la solution d’origine, celle avec colonne temporaire, puis voyons les modifications que nous y avons apportées.
Étape 1 : convertir les données en tâche de fond
La commande ALTER TABLE foo ALTER COLUMN id SET DATA TYPE BIGINT effectue (entre autres) une conversion des données (cast) de INTEGER à BIGINT.
La documentation mentionne en effet :
Changing the type of an existing column will require the entire table and its indexes to be rewritten. As an exception, when changing the type of an existing column and the old type is either binary coercible to the new type a table rewrite is not needed; but any indexes on the affected columns must still be rebuilt. Table and/or index rebuilds may take a significant amount of time for a large table; and will temporarily require as much as double the disk space.
Comme l’opération native pose un verrou exclusif sur la table, il faut attendre sa réécriture complète pour y accéder.
An ACCESS EXCLUSIVE lock is held unless explicitly noted.
L’alternative à la solution native est d’effectuer la conversion des données en tâche de fond :
- dans une colonne de type BIGINT, non exposée à l’API ;
- pour les nouveaux tuples, à l’aide d’un trigger ;
- pour les tuples existants, par un traitement batch.
Étape 2 : substituer les colonnes et créer la clef primaire
Une fois la migration achevée, une fenêtre de maintenance est requise (1h dans le cas d’origine) pour :
- supprimer les contraintes sur la colonne INTEGER (PK, FK) ;
- promouvoir la colonne de type BIGINT en tant qu’identifiant ;
- recréer les contraintes (PK et FK).
Améliorations
Cette solution va dans le bon sens, mais ne satisfait par tous nos critères : il reste une fenêtre de maintenance. Nous pensons qu’il est possible de pousser la solution et d’éliminer totalement cette fenêtre.
Le principe est le suivant :
- la contrainte de clef primaire comporte une contrainte NOT NULL et une contrainte UNIQUE ;
- c’est la validation de ces contraintes qui prend le plus de temps dans la fenêtre de maintenance ;
- ces validations peuvent être effectuées en amont.
Pour valider les contraintes en amont :
- ajouter une contrainte NOT NULL dès la création de la colonne ;
- créer un index UNIQUE de manière concurrente
CREATE INDEX CONCURRENTLY.
Il ne reste plus, comme dernière opération, qu’à créer la PK sur base de l’index UNIQUE.
ALTER TABLE "foo" ADD CONSTRAINT "foo_pkey" PRIMARY KEY USING INDEX "foo_id_unique"
PostgreSQL détecte lui-même la contrainte NOT NULL.
Implémentation
Le code présenté a été modifié pour les besoins de l’article, mais un lien est fourni vers chaque commit pour les détails.
A l’état initial, la table contient 700 millions d’enregistrements. fd7273f9
CREATE TABLE "knowledge-elements"(
id SERIAL PRIMARY KEY,
source varchar(255),
(...)
);
La première étape est l’ajout d’une colonne temporaire, avec une migration de BDD, incluse dans le déploiement de la release. eecfd941
ALTER TABLE "knowledge-elements" ADD COLUMN "bigintId" BIGINT NOT NULL DEFAULT -1;
Puis, un trigger est créé pour alimenter la valeur pour les nouveaux enregistrements.
CREATE OR REPLACE FUNCTION copy_int_id_to_bigint_id() RETURNS TRIGGER AS $$ BEGIN NEW."bigintId" = NEW.id::BIGINT; RETURN NEW; END $$ LANGUAGE plpgsql;
CREATE TRIGGER "trg_knowledge-elements" BEFORE INSERT ON "knowledge-elements" FOR EACH ROW EXECUTE FUNCTION copy_int_id_to_bigint_id();
Ensuite, le script de migration inclus dans la PR est lancé manuellement (durée: 48h pour 700 millions de lignes). d89cb206
const data = await client.query('SELECT MAX(id) FROM "knowledge-elements"');
const startId = 0;
const endId = maxData.rows[0].max;
for (let id = startId; id < endId; id += chunkSize) {
const result = await client.query(`
UPDATE "knowledge-elements"
SET "bigintId" = id
WHERE ID BETWEEN ${id} AND ${id + chunkSize - 1}`);
}
await client.query('CREATE UNIQUE INDEX CONCURRENTLY "indexidBigInteger"');
Pour finir, une dernière migration, celle qui expose la colonne BIGINT 9985cafe
BEGIN TRANSACTION;
LOCK TABLE "knowledge-elements" IN ACCESS EXCLUSIVE MODE;
DROP TRIGGER "trg_knowledge-elements" ON "knowledge-elements";
DROP FUNCTION "copy_int_id_to_bigint_id";
ALTER SEQUENCE "knowledge-elements_id_seq" OWNED BY "knowledge-elements"."bigintId";
ALTER SEQUENCE "knowledge-elements_id_seq" AS BIGINT;
ALTER TABLE "knowledge-elements" ALTER COLUMN "bigintId" SET DEFAULT nextval('"knowledge-elements_id_seq"');
ALTER TABLE "knowledge-elements" ALTER COLUMN "id" DROP DEFAULT;
ALTER TABLE "knowledge-elements" DROP CONSTRAINT "knowledge-elements_pkey";
ALTER TABLE "knowledge-elements" ALTER COLUMN "id" DROP NOT NULL;
ALTER TABLE "knowledge-elements" ADD CONSTRAINT "knowledge-elements_pkey" PRIMARY KEY USING INDEX "knowledge-elements_bigintId_index";
ALTER TABLE "knowledge-elements" RENAME COLUMN "id" TO "intId";
ALTER TABLE "knowledge-elements" RENAME COLUMN "bigintId" TO "id";
COMMIT TRANSACTION;
Validation de la solution
Cette hypothèse de solution a été mise progressivement en contact avec la réalité, pour garder un feedback rapide :
- exécution sur une table de test, ne comportant qu’une seule colonne, sur une volumétrie comparable à la production ;
- même test, en soumettant la BDD à des requêtes concurrentes de lecture/écriture sur la table pour estimer l’impact sur les temps de réponse ;
- exécution sur une copie de la table de production ;
- même test, en soumettant la BDD à un échantillon des requêtes de production sur la table pour estimer l’impact sur les temps de réponse ;
- intégration du code dans le processus de migration de BDD (knex) ;
- déploiement du code, via le processus de migration, sur une instance de reporting de production.
Les apprentissages ont été les suivants :
- l’intégration maximale au processus de déploiement augmente la fiabilité ;
- les tests menés dès le début ont entraîné la mise en place au plus tôt d’un monitoring (extension pg_stat_statements + Datadog) sur :
- la vitesse de la migration et sa date de fin estimée;
- les temps de réponse BDD et API;
- la pertinence des tests est limitée par:
- la capacité de reproduire un trafic similaire à la production ;
- le fait que l’environnement soit sur une plateforme dédiée, avec une disponibilité des ressources partagée (ex: I/O) non déterministe.
Exécution en production et perspectives
Le plan se déroule sans accroc
La migration préalable s’est déroulée sans erreur.
La migration des données proprement dite a pris environ 24h.
L’exposition de la nouvelle colonne, lors du déploiement, a pris un temps négligeable pour les utilisateurs finaux (< 1 seconde).
2021-08-27 14:10:40.368443479 +0200 CEST [postdeploy-2719] > pix-api@3.92.0 postdeploy /app
2021-08-27 14:10:40.368393446 +0200 CEST [postdeploy-2719]
2021-08-27 14:10:41.566685265 +0200 CEST [postdeploy-2719] Batch 188 run: 1 migrations
2021-08-27 14:10:42.176473412 +0200 CEST [manager] container [postdeploy-2719] (6128d63ffcff1013ac9e57c1) has stopped
Mais
Un impact non négligeable du traitement de migration sur le temps de réponse
Bien que l’opération soit un succès, lors des étapes préparatoires :
- le temps de réponse de l’API a augmenté d’un facteur 10, en passant d’une moyenne de 70 ms à 1 000 ms ;
- lors de l’étape de migration des données, ont eu lieu 4 pics à 3 secondes, d’une demi-heure chacun ;
- lors de l’étape de validation des contraintes, a eu lieu 1 pic à 10 secondes, d’une heure et demie.
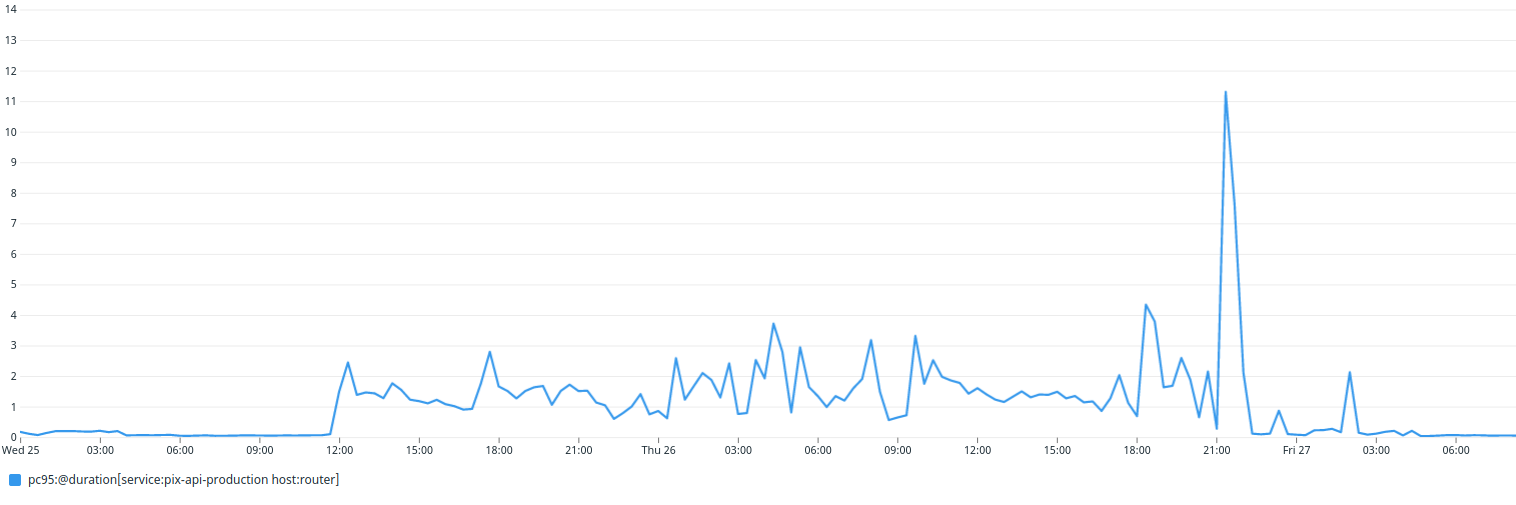
Malgré cela, l’impact utilisateur a été faible, car :
- cela eu lieu en été, période de faible fréquentation de la plateforme ;
- le plus long pic a eu lieu à un horaire de faible fréquentation (nuit).
Si l’impact utilisateur s’était avéré plus fort, nous aurions ralenti le traitement en réduisant :
- la taille des batchs ;
- le rythme d’exécution (pauses périodiques).
Un impact sur l’organisation des données sur le disque
Nous avons constaté que la table est bien plus fragmentée après migration qu’avant migration. Bien que nous n’ayons pas fait de test comparatif, il est possible que cela soit dû à notre solution.
En effet :
- la solution native réécrit la table en une seule fois ;
- notre solution la réécrit en plusieurs fois.
Cela peut avoir deux effets :
- occupation de disque plus importante ;
- impact sur les temps de réponse.
Nous monitorons actuellement les temps de réponse pour déterminer s’il y a un impact.
Perspectives
Nous avons prévu de changer le type d’identifiant sur d’autres tables. Nous ne pourrons pas appliquer exactement la même approche à l’avenir, pour deux raisons qui seront détaillées. Aussi, nous allons continuer à y travailler et cela fera l’objet d’un nouvel article.
Diminuer les impacts possibles
Le contexte de faible fréquentation de la plateforme ne peut pas être pris comme un pré-requis.
Nous pensons à :
- rendre le traitement de migration paramétrable à chaud, en passant de variables d’environnement à une table de paramétrage.
- modifier notre approche en passant d’une colonne temporaire à une table temporaire .
Généraliser la solution
“Rudy’s Rutabaga rule” de Gerald Weinberg nous dit
Once you eliminate your number one problem, number two gets a promotion.
Notre problème n°2 est une table dont l’identifiant :
- dont le type doit aussi être modifié en BIGINT ;
- est référencé par une autre table (FK).
Nous allons réutiliser le principe de “faire le maximum en amont” sur cette nouvelle situation :
- deux colonnes à mettre à jour au lieu d’une ;
- une contrainte de type FK en plus de la contrainte de type PK.
Des suggestions d’amélioration ?
Afin de rester sur un format court, cet article :
- prend comme pré-requis le MVCC de PostgreSQL, et ses conséquences lors d’ajout et de suppression de colonne (bloat) ;
- ne précise pas la raison des détails d’implémentation, notamment du script de migration des données.
Si vous avez des questions, contactez-nous pour que nous puissions améliorer cet article !