Legacy code

TL;DR
Lorsque la seule stratégie de test est manuelle, et uniquement sur la production, un bug peut couper le service. Cet article décrit comment nous sommes passés de cette situation risquée à une solution classique, avec plusieurs environnements et des tests automatisés. Nous y sommes arrivés en appliquant la démarche de Michael Feathers, qui sera présentée.
Motivation
Chez Pix, les mises en production suivie de revert sont rares. Quand cela arrive, on en tire des leçons.
CHERISH YOUR BUGS. STUDY THEM. @Systems Bible
La ligne ci-dessous a introduit un bug.
await client.query('CREATE MATERIALIZED VIEW metabase-answers AS SELECT * FROM "answers" WHERE "createdAt" >= (now() + INTERVAL \'-15 days\')');
Pour ceux qui ne parlent pas couramment le PostgreSQL, l’erreur n’est pas dans l’opération de date, mais sur l’emploi
du tiret. \'metabase-answers\' ou metabase_answers auraient fait l’affaire. Mais ce n’est pas cet apprentissage
que nous voulons partager.
Ce que nous voulons partager, c’est qu’entre l’introduction de l’erreur et la correction :
- le service a été interrompu pour l’ensemble des 300 utilisateurs;
- une journée s’est déroulée;
Autrement dit :
- pourquoi a-t-on une boucle de rétroaction aussi longue ?
- comment la raccourcir ?
D’où est-ce qu’on part ?
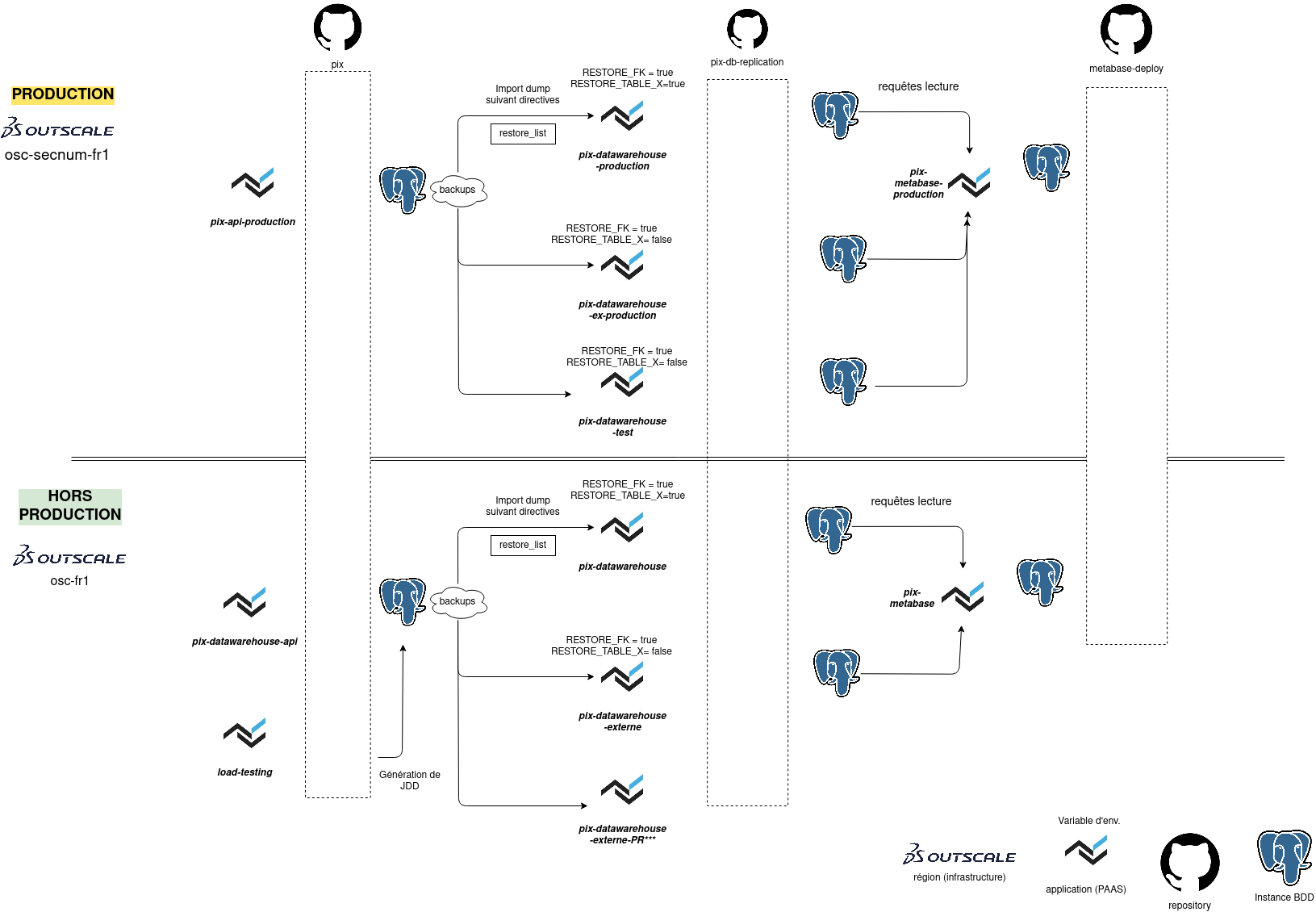
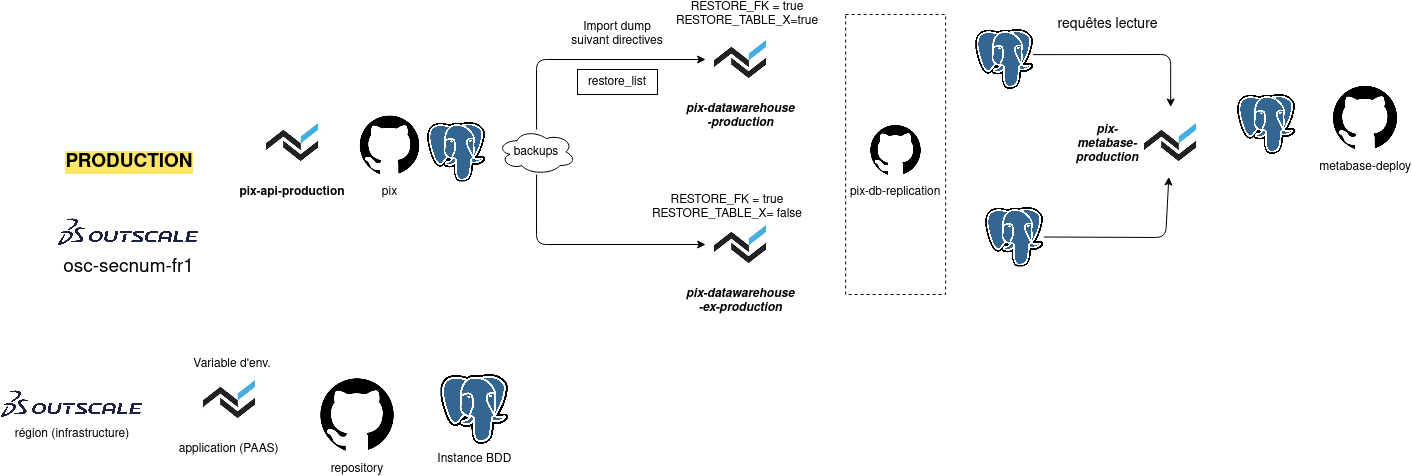
Contexte
La plateforme pix.fr permet à tout citoyen d’évaluer et de développer ses compétences numériques. C’est une SPA servie par une API REST exploitant une base de données relationnelle.
Afin de mieux connaître les besoins des utilisateurs, une plateforme décisionnelle a été constituée, incluant notamment Metabase. Pour ne pas impacter la performance et l’intégrité de la base de donnée principale, une base de données dédiée a été créée. Elle est alimentée chaque nuit en copiant la base de données principale (par un dump, le schéma détaillé est disponible ici).
Besoin fonctionnel
Au fur et à mesure du temps, cet import de données prend de plus en plus de temps. Juste avant notre intervention, les données n’étaient disponibles que vers 14h, alors que l’import lui-même démarrait à 4h du matin le jour même. Nous souhaitons disposer de ces données beaucoup plus tôt, dès le début de la journée de travail.
Nous souhaitons aussi que ce changement se passe mieux qu’auparavant :
- livrer une fonctionnalité vérifiée;
- limiter l’interruption de service.
Besoin technique
Nous ne disposons :
- que d’un seul environnement, celui de production;
- que d’un seul type de test, le test manuel.
Nous souhaitons sortir de cette situation en :
- pouvant exécuter le code ailleurs (au moins en local);
- disposant de tests automatisés.
Cela permettrait d’ailleurs des tâches anodines, mais précieuses, comme la mise à jour des dépendances
(ex : la version du package execa a 4 ans de retard).
Au travail
Disposer d’environnements hors production
Ce que l’on tient pour acquis peut tenir du miracle dans un autre contexte. Dans mes expériences professionnelles précédentes, obtenir un serveur applicatif prenait un an. Il était d’ailleurs impensable de disposer de base de données en local, vu le coût des licences.
Mais ici, nous disposons d’un Paas et PostgreSQL est open-source. Au bout d’une demi-journée, les environnements suivants sont prêts :
- local avec plusieurs base de données;
- de revue de code (review-app);
- d’intégration pour constituer des releases;
- de pré-production.
Le schéma détaillé est ici.
L’environnement de pré-production est alimenté par la même source de données que la production, afin de pouvoir effectuer si besoin des tests de performance.
Implémenter la nouvelle fonctionnalité
Le principe
Nous commençons par tester la viabilité de la solution technique avec un POC réalisé sans tests.
Si les essais sont concluants, nous passons à l’approche de Michael Feathers :
- écrire un test sur le comportement existant (si besoin, casser des dépendances);
- implémenter la nouvelle RG.
Si vous voulez en savoir plus sur l’approche de Michael Feathers, des détails se trouvent en fin d’article.
Un POC
La solution technique a été implémentée et testée en pré-production en 2 jours dans cette PR.
Pour les intéressés, la solution technique est de passer, pour certaines données, d’un import par dump à une recopie des données via le réseau (simili DBLink), voir COPY stdin/stdout. La modification effective fait 64 lignes
Tester le code à modifier
Le comportement principal de l’application est constitué d’effets de bord en base de données. Nous avons utilisé le framework de
test habituel (mocha/chai). Plutôt que de reprendre la couche d’accès habituelle aux données de pix
(knex + node_postgres),
nous sommes passés par le client natif psql. Celui-ci est appelé par NodeJS via la librairie execa.
La PR obtenue fait 300 lignes.
Implémenter la fonctionnalité
Nous n’avions pas anticipé que les tests existants ne se prêteraient pas bien à être modifié pour la nouvelle fonctionnalité. En effet, le jeu de données en entrée passait d’un simple dump à une base de données source qui devait exister en même temps que la base de données cible. Nous avons donc poursuivi par une PR de refactoring des tests suivant le dicton de Kent Beck :
For each desired change, make the change easy (warning: this may be hard)
Then make the easy change
Ces +200/-100 ont nous bien fait réfléchir !
Nous avons ensuite ajouté la fonctionnalité déjà disponible dans le POC. Cette dernière PR nous a fait éprouver ce que tout développeur a expérimenté au moins une fois : Globals are evil
Et ensuite ?
Le plus dur était fait ! Après un test en pré-production, la mise en production a été un non-événement.
Un boulevard s’ouvrait désormais pour améliorer la codebase en toute sérénité :
- Activer la CI
- casser les dépendances temporelles pour éviter des indisponibiltés
- casser d’autres dépendances en passant d’un CLI à un API
Annexes
Working effectively with legacy code
Je vous recommande vivement le livre Working effectively with legacy code (2005) de Michael Feathers. Pour ceux qui ne l’ont pas lu, ou souhaitent se rafraîchir la mémoire, voilà un résumé sous la forme d’une interview imaginaire dont les réponses sont tirées du livre.
Notes :
- dans ce dialogue, seules les réponses sont de Michael Feathers;
- mes compétences de traducteur étant limitées, la version anglaise originale avec les renvois de page suit.
Une interview imaginaire
Qu’est-ce que le “legacy code” ?
Dans l’industrie, “legacy code” * est un terme argotique pour désigner du code difficile à modifier que l’on ne comprend pas. (…) En ce qui me concerne, “legacy code” c’est simplement du code sans tests. (p. xvi)
NDT: Je n’ai pas traduit le terme de “legacy code”, malgré les possibilités, car aucun usage ne s’est imposé.
Pourquoi s’y intéresser ?
Il y a deux manières de modifier un système. Je les appelle “Modifie et prie” et “Assure tes arrières avant de modifier”. De l’extérieur, “Modifie et prie” peut passer pour “travailler avec attention”, qui est une attitude vraiment professionnelle. (…) Mais la sécurité ne dépend pas que de l’attention. Je ne connais personne qui choisirait d’être opéré par un chirurgien qui opèrerait avec un couteau à beurre *, uniquement parce qu’il travaille avec attention. (p.9)
NDT: Le couteau à beurre est plus proche d’une spatule que d’un couteau.
Le fait d’avoir des tests facilite donc les modifications ?
Le code sans test * est mauvais. Peu importe qu’il soit bien écrit; peu importe à quel point il est élégant, orienté-objet ou encapsulé. Avec des tests, nous pouvons changer le comportement de notre code rapidement et de manière fiable. Sans eux, nous ne pouvons pas réellement savoir si l’état du code s’améliore ou empire. (xvi)
NDT: Les tests mentionnés ici sont les vérifications automatisés du code, pas les tests manuels.
Est-ce que n’importe quel type de test fait l’affaire ?
En fait, ce type de test * est “Tester pour essayer de prouver”. Bien que ce soit un objectif respectable, les tests peuvent aussi être utilisés de manière très différente. Nous pouvons “tester pour détecter le changement”, ce que la tradition désigne comme “test de régression”. Une fois que vous avez posé des tests autour de la zone sur laquelle vous allez intervenir, ils jouent le rôle d’un étau logiciel (p.10)
NDT: L’auteur fait référence aux tests concernant la fonctionnalité qui a été ajoutée
Dans ce cas, je vais tout de suite écrire ces tests !
Il y a un léger problème avec les tests de régression. La plupart du temps, quand les développeurs en créent, ils le font au niveau de l’application. C’est une très mauvaise idée.(..) Est-ce que vous préférez avoir une rétroaction dans une minute ou dans plusieurs heures ? Le test unitaire est une des pratiques les plus importantes dans le travail sur le “legacy code”. Les tests de régression au niveau système sont utiles, mais des tests de petite taille et localisés, cela n’a pas de prix. (p.10)
D’accord, mais je ne peux pas commencer par écrire des tests unitaires de régression pour toute la base de code. Je ne m’appelle ni Hercule ni Sisyphe !
L’objectif de tous les jours dans le “legacy code” est de faire des changements, mais pas n’importe lesquels. Nous voulons à la fois faire des changements fonctionnels qui ajoutent de la valeur, et amener le système à être contrôlé par les tests. (…) Au fur et à mesure, les zones testées de la base de code finissent par faire surface comme des îles qui émergent de l’océan. Travailler sur ces îles devient de plus en plus facile. (p.18)
Un autre conseil avant de me lancer ?
Les dépendances constituent le plus souvent le plus grand obstacle aux tests. La plupart du temps, dans le “code legacy”, il est nécessaire de casser les dépendances pour ajouter des tests. Dans un monde idéal, nous aurions des tests qui empêcheraient les régressions lorsque nous cassons les dépendances, mais la plupart du temps nous n’avons pas ces tests. (p.19)
Source
What is legacy code ?
In the industry, legacy code is often used as a slang term for difficult-to-change code that we don’t understand. (…) To me, legacy code is simply code without tests. (p. xvi)
What’s interesting about it ?
Changes in a system can be made in two primary ways. I like to call them “Edit and Pray” and “Cover and Modify”. Superficially, “Edit and Pray” seems like “working with care”, a very professional thing to do. (…) But safety isn’t solely a function of care. I don’t think any of use would choose a surgeon who operated with a butter knife just because he worked with care. (p.9)
So we need tests to make changes more easily ?
Code without tests is bad code. It doesn’t matter how well written it is; it doesn’t matter how pretty or object-oriented or well-encapsulated it is. With tests, we can change the behavior of our code quickly and verifiably. Without them, we really don’t know if our code is getting better or worse. (xvi)
Would any kind of tests do ?
Testing done this way is really “Testing to attempt to show correctness”. Although that is a good goal, tests can also be used in a very different way. We can do “testing to detect change”. In traditional terms, this is called regression testing. When you have tests around the areas in which you are going to make changes, they act as a software vise. (p.10)
Can I start writing such tests right now ?
There is a little problem with regression testing. Often, when people practice it, they do it at the application interface. But this is very unfortunate. (..) Do you want your feedback in a minute or overnight ? Unit testing is one the most important components in legacy code work. System-level regression tests are great, but small, localized test are invaluable. (p.10)
Ok, but we can’t write regression unit test for the whole codebase at once. We’re neither Hercules nor Sisyphus !
The day-to-day goal of legacy code is to make changes, but not just any changes. We want to make functional changes that deliver value while bringing more of the system under test. (…) Over time, tested areas of the codebase surface like islands rising out of the ocean. Work in these islands becomes much easier. (p.18)
Ok, is that all before we start ?
Dependencies are often the most obvious impediment to testing. Often, in legacy code, you have to break dependencies to get tests in place. Ideally, we would have test that tell us whether the things we do to break dependencies cause problems, but often we don’t. (p.19)
Environnements
Avant
Après